Here we present BINGO’s collected EEG data with the aim to cover two basic aspects of inner speech decoding research:
i) A complete and large-scale dataset that supports a wide variety of words (also capable of acting as a generic spelling corpus)
ii) A dataset capable of driving research among the neural interconnections between inner speech in two distinct languages.
Below we provide a short description (details provided in D3.1 v2) of the employed experimental protocols and links to access the corresponding datasets.
DATASET 1: NATO PHONETIC ALPHABET – CLASSIFICATION TASK (Due to pending Kaggle competition data currently unavailable)
The inner speech task was designed using the NATO phonetic alphabet (shown in the Figure below) as a structured linguistic framework to elicit neural responses associated with silent speech production. This approach ensured a controlled and standardized set of stimuli with a diverse phonological. The NATO alphabet constitutes an exceptional opportunity for serving as the basis for inner speech decoding (using solely EEG signals) at a word level but also may serve as a generic alphabet where typing in a letter-by-letter setting can be realized.

Prior to beginning the recording session, all subjects (20 in total) were able to hear the pronunciation of the NATO words so as to minimize the variability across phonological representations. The task incorporated visual cues to prompt participants to internally articulate specific phonetic words without overt speech or subvocalization. The selection of sole visual cues during the recording process minimizes the contamination of brain signals stemming from brain areas highly involved in inner speech (e.g. Broca’s area).
Each participant, attended the experimental protocol three times, each time taking place in a different day (referred to as Day1, Day2, and Day3). During the first day, words corresponding to the letters A-M were recorded (35 times per word per participant), whereas the rest (N-Z) during Day 2 (35 times per word per participant). In the third and last day, all the words were recorded again (10 times per word per participant) so as to serve as the test set.
DATASET 2: CROSS-LINGUISTIC INNER SPEECH ELICITATION (Access Link)
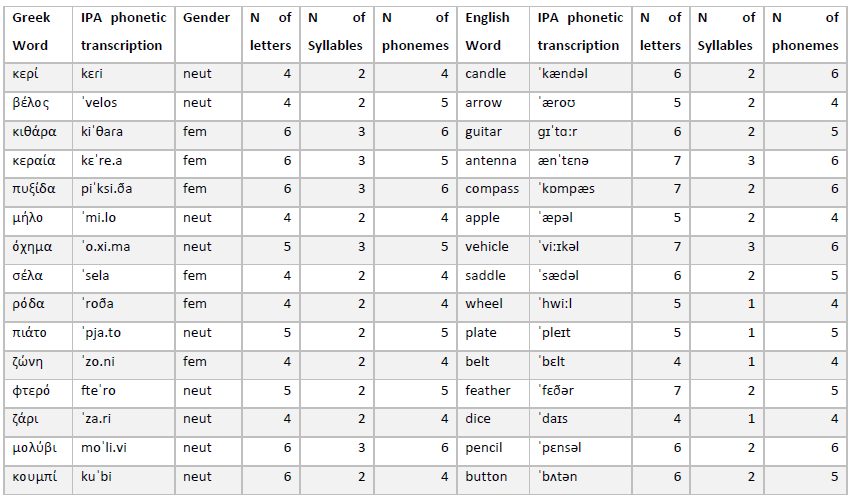
In cross-linguistic paradigms, additional constraints arise from differences in orthographic transparency between languages. Greek is a relatively transparent (shallow) orthography with consistent grapheme–phoneme mappings, whereas English is a deep orthography with more ambiguous mappings. Consequently, matching stimuli solely on the basis of number of letters or syllables would be insufficient; phoneme-based word-length matching is more appropriate for ensuring comparable processing demands across languages.
Considering the above, for the purposes of the present study, we consider the factors of word-length, frequency and features involved. Specifically, we identified 15 words in English and Greek controlling for the following lexical features [+Nouns], [-Human], [-Animate], [+Concrete], [-Ambiguous], [+Countable], [+Singular]. The trials selected are up to three syllables long and are matched in word-length measured in N of phonemes as there are differences with regard to the orthographic transparency of the two languages (MGR = 4.73, SDGR = 0.79; MENG = 5.00, SDENG = 0.84; t(28) = -.888, p =.382). With regard to frequency, we opted for everyday lexical items consulting the items included in standardized test for lexical ability screening; Peabody Picture Vocabulary Test – PPVT and Renfrew Word Finding Vocabulary Test. With regard to grammatical gender in Greek, masculine nouns were excluded since the lexical features and word-length criteria for inclusion were not met; the finalized trial set includes nine (9) neuter and six (6) feminine nouns. The list of items per language appears below: